“Everything should be made as simple as possible, but not simpler.” - Albert E
Read More
Read More“Any measurement you make, without knowledge of its uncertainty, is completely meaningless.”
- Prof. Walter Lewin, MIT Physics 101
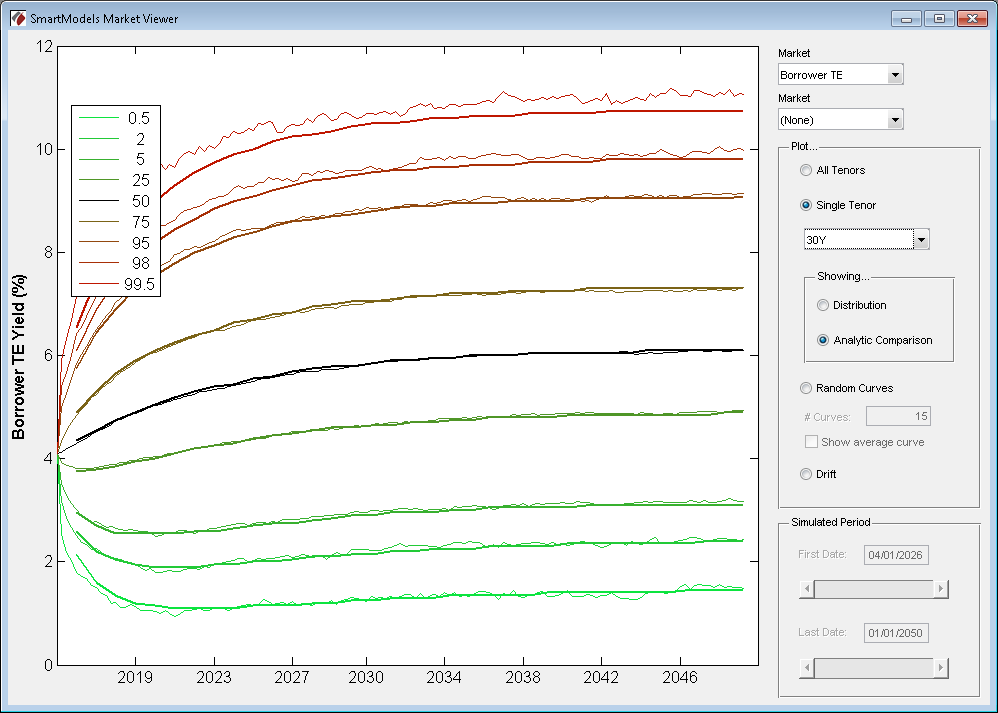
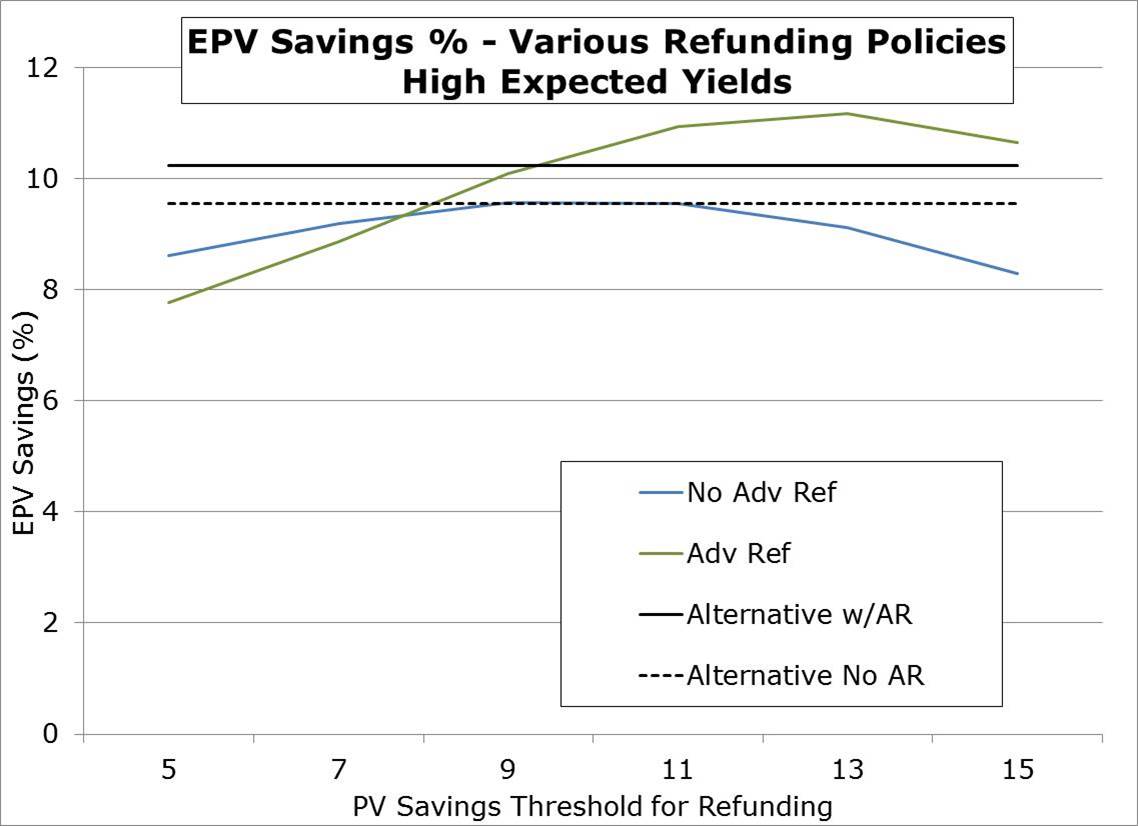
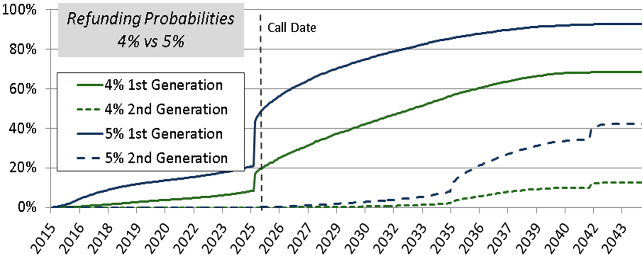
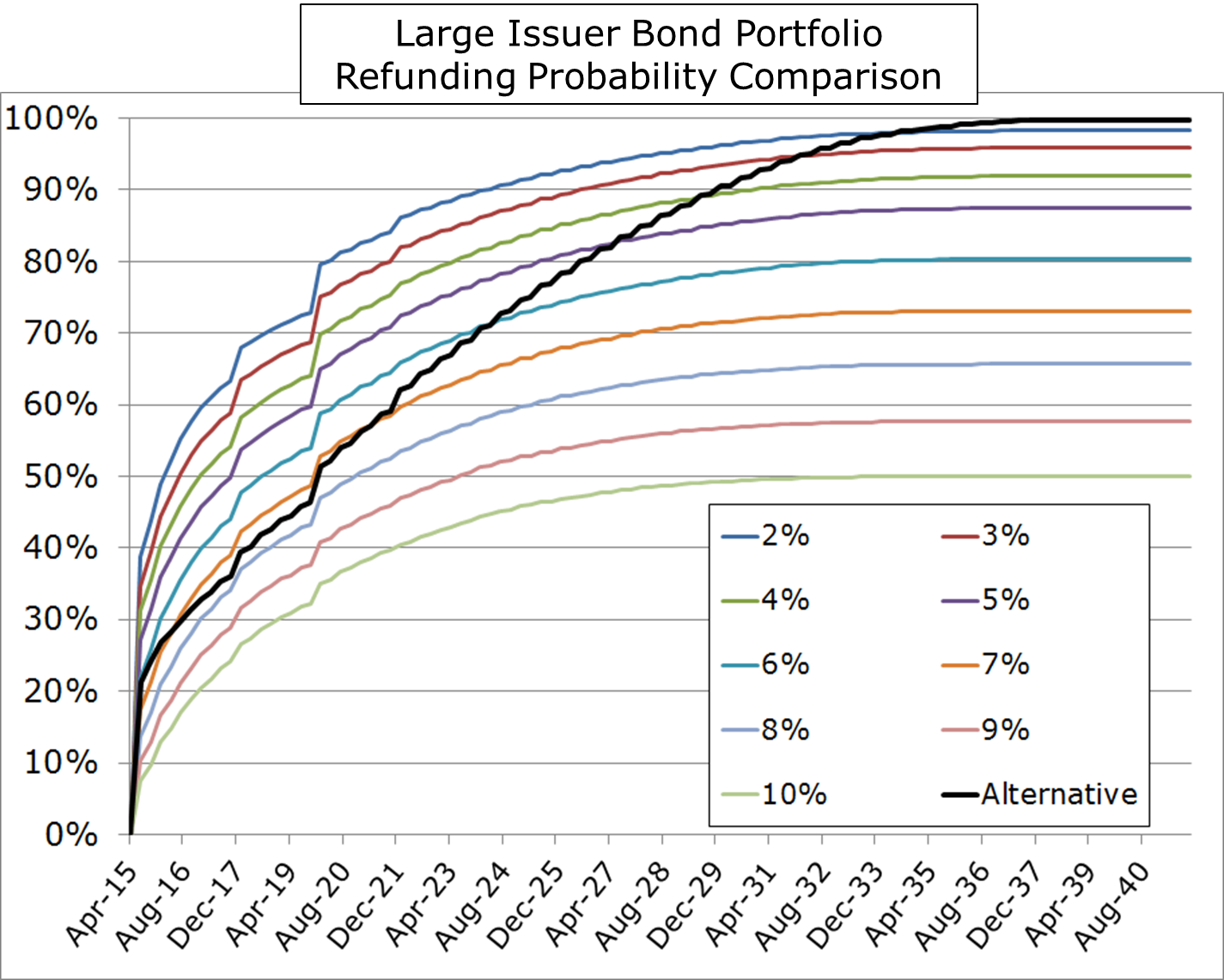
We’ve written a number of articles talking about financial forecasting being a necessary evil, implied forward yields being miserable predictors of realized yields, and recently the inappropriate use of option pricing models (requiring market-based inputs) when doing refunding analysis. We even wrote a paper on it as we see a lot of misunderstanding by pubfin practitioners on this point.
Read MoreTopics: financial forecasting, press
Read More"I don't think necessity is the mother of invention. Invention, in my opinion, arises directly from idleness, possibly also from laziness - to save oneself trouble."
- Agatha Christie
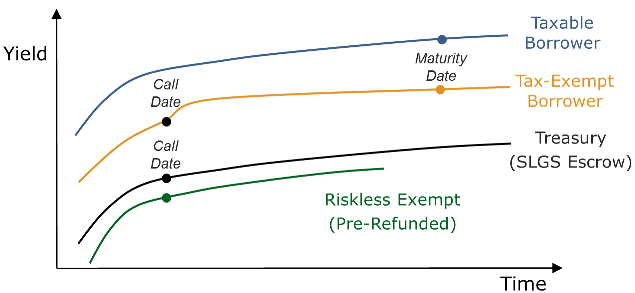
Yesterday I spoke at a luncheon (many thanks to MAGNY for a great event) where, during Q&A, a number of people commented on how difficult it is for those who grew up doing corporate bonds to try to cross over into muni-land’s veritable Oz. With all the talking trees and flying monkeys, munis can be pretty disorienting. And I’ve seen it happen many times myself; graveyards are indeed littered with the corpses of corporate types who come to munis and just never get it, both on the buy-side and the banker/sell-side. They show up bright-eyed and bushy-tailed talking about “benchmark this” and “OAS that” but ultimately wind up crouched in a corner mumbling something about 5 and 10 year bullets.
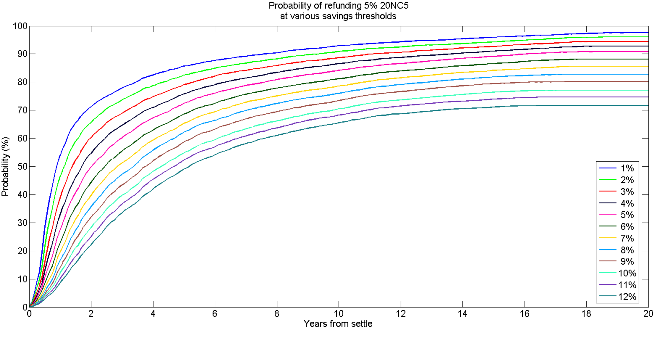
“I have two ways of learning from history: from the past, by reading the elders; and from the future, thanks to my Monte Carlo toy.”
- Nassim Taleb, Fooled by Randomness

In Part 1 (a suggested read if you’re getting to this article first) we proposed 3 questions that determine whether bond option pricing models, in contrast to real-world option models, are appropriate for tax-exempt issuers analyzing their callable bonds: